C#进阶之重要知识点补充
C#进阶之重要知识点补充
一、泛型
1. 泛型是什么
- 泛型实现了
类型参数化,达到代码重用的目的,通过类型参数化来实现同一份代码上操作各种类型。- 解释:
- 泛型相当于
类型占位符- 定义类或者方法时,可以使用
替代符等代表变量类型- 当真正使用类或者方法时再具体指定类型
- 说白了就是
类型参数化
2.泛型分类
- 泛型类
* 基本语法:
- 泛型接口
* 基本语法: * ```c# interface 接口名 <泛型占位字母>
2
3
4
5
6
7
8
9
10
* 泛型函数
* 基本语法:
* ```c#
函数名<泛型占位字母>(参数列表)
{
//函数体
}
注意:
泛型占位字母可以有多个,必须用逗号隔开。* 具体实现如下
2
3
4
5
6
7
8
{
public T1 a;
public T2 b;
public T3 c;
}
//主函数创建泛型类
public Test2<int,float,string> player=new Test2<int,float,string>();* 泛型类中的泛型方法(`泛型类方法`)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
//普通类中的泛型方法
public void TestFun<T>(T value)
{
//函数体
}
public void TestFun<T>()
{
//用泛型类型 在里面做一些逻辑处理
T t=default(T);//default()可以获得当前类型的默认值
}
public T TestFun<T>(string v)
{
//用于返回值
return default(T);
}
public void TestFun<T>(T v,T k,T j)
{
//多个参数
}
}
2
3
4
5
6
7
8
9
10
11
12
{
public T value;
//这个不叫泛型方法 因为 T是泛型类申明的时候 就
//指定 在使用这个函数的时候 我们不能动态的变化了
public void TestFun(T t)
{
//函数体
}
//只有方法+尖括号才能叫泛型方法
//wqx取名为泛型类方法
}
3.泛型的作用
* (1).不同类型对象的相同逻辑处理就可以选择泛型
- (2).使用泛型可以一定程度避免装箱拆箱
- 举例:
优化ArrayList
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
private T[] array;
//因为ArrayList是object数组,既可以指定类型
//又可以避免装箱拆箱
public void Add(T value)
{
//typeof(int);可以获取目标类型,可以用于判断类型
if(typeof(int)==typeof(T))
{
}
}
public void Remove(T value)
{
}
}
4.总结
- 申明泛型时 ,它只是一个类型的占位符
- 泛型真正起作用时候 ,是在使用他的时候
- 泛型占位字母可以用n个逗号分开
- 泛型占位字母一般是大写字母
- 不确定泛型的类型时 获取默认值 可以使用default(占位字符)
- 看到<>包括的字母 那肯定是泛型
二、泛型约束
1.什么是泛型约束
2.各种泛型约束详解
(1).值类型约束
* 实现代码如下:
2
3
4
5
6
7
8
{
public T value;
public void TestFun<K>(K v) where K:struct
{
//函数体
}
}
(2).引用类型约束
实现代码如下
2
3
4
5
6
7
8
{
public T value;
public void TestFun<K>(K v) where K:class
{
//函数体
}
}
(3).公共无参构造函数约束(非抽象类型)
泛型代码如下:
2
3
4
5
6
7
8
{
public T value;
public void TestFun<K>(K v) where K:new()
{
//函数体
}
}测试类代码:
2
3
4
5
6
7
8
9
10
{
//默认自带无参构造
}
class Test2
{
public Test2(int a){
}
}主函数
2
Test3<Test2> t1=new Test3<Test2>(1);//报错注意 :
一定是公共构造函数,也可以填结构体,抽象类也不行
因为结构体就算写了无参构造,也不会被顶掉
详细见《结构体与类的区别》 跳转
(4).类约束
泛型代码如下
2
3
4
5
6
7
8
{
public T value;
public void TestFun<K>(K v) where K:Test1
{
//函数体
}
}派生类(子类)
2
3
4
{
}主函数
2
Test4<Test3> t2=new Test3<Test>();//正常
(5).某个接口的派生类型
泛型代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
}
class Test4:IFly
{
}
class Test5 <T> where T:IFly
{
public T value;
public void TestFun<K>(K v) where K:IFly
{
//函数体
}
}
注意:
接口是new不出来的,所以只能传入接口派生的类或者接口,但是不会报错,没办法使用类里面抽象类型的成员,因为不能new主函数
2
3
4
//可以运行,但是这么写是错的
//要传入接口派生类
Test5<Test4> t5=new Test5<IFly>();
思考:为什么可以传入派生类因为里氏替换原则;父类可以被子类替换,父类里面的东西子类全都有。
(6).另一个泛型类型本身或者派生类型
- 泛型代码
2
3
4
5
6
7
8
{
public T value;
public void TestFun<K,V>(K v) where K:V
{
//函数体
}
}
主函数调用
2
Test6<Test4,IFly> t6=new Test6<Test4,IFly>();
理解:约束泛型类型U是T的类型本身或者是T的派生类型
3.约束的组合使用
- 每种约束可以用逗号连接,叠加在一起使用
- 想怎么用怎么用,自己去试,不需要排列组合
- 根据自己的需求去找出配套的组合
- 发现报错就换一种
2
3
4
{
//约束就是,类里面必须要有无参构造
}
注意:new(),带括号的要放在最后面,不然会报错
4.多个泛型有约束
- 直接在后面where接着写
注意:不要加逗号
2
3
4
{
}
5.总结
- 泛型约束:让类有一定的限制
- class,struct,new(),类名,接口名,另一个泛型字母
- 注意:
- (1).可以组合使用
- (2).多个泛型约束 ,用where连接即可。
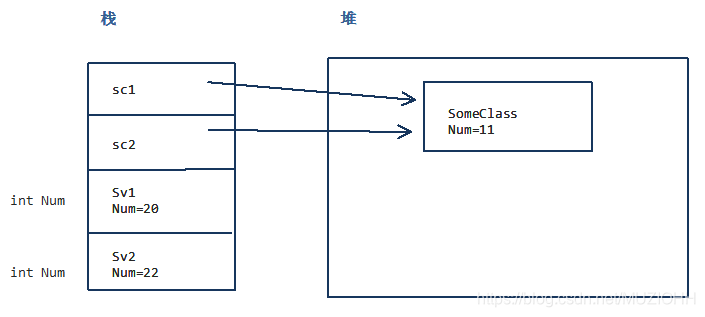
三、值类型和引用类型补充
- 值类型和引用类型的
本质区别:- 值的具体储存在栈内存上
- 引用的具体内容储存在堆内存上
| 栈内存 | 堆内存 | ||
|---|---|---|---|
| 1000(int) | 类内容 | 地址1 | |
| 1004(int) | |||
| (地址1)(类) |
1.问题一 如何判断 值类型和引用类型
- F12进到类型的内部
- 是class就是引用
- 是struct就是值
2.问题二 语句块

- 上层语句块:类,结构体
- 中层语句块:函数
- 底层语句块:条件分支,循环等
(1)我们的逻辑代码写在哪里?
- 函数、条件分支、循环—-中底层语句块中
(2) 我们的变量可以申明在哪里?
- 上、中、底都能申明变量
- 上层语句块中:成员变量
- 中、底层语句块中:临时变量
3. 问题三 变量的生命周期
- 编程时大部分都是
临时变量- 在中底层申明的临时变量(函数,条件,循环)语句块执行结束后
没有被记录的对象将被回收或变为垃圾- 值类型:被系统自动回收,(弹栈)
- 引用类型:栈上用于存地址的房间被系统自动回收,堆中具体内容变成垃圾,待下一次GC清理
- 想要不被回收或者不变垃圾
- 必须将其
记录下来- 如何记录?
- 在更高层级记录
- 使用静态全局变量记录
2
3
4
5
6
7
8
9
{
int b=0;
public static int TestI;
public void Fun()
{
b=1;
}
}
4.问题四 结构体中的值和引用
结构体本身是值类型
前提:
该结构体没有做为其他类的成员在结构体中的值,栈中存储值具体的内容
在结构体中的引用,堆中存储引用具体的内容
引用类型始终存储在堆中
真正通过结构体使用其中引用类型时只是
顺藤摸瓜总结:也就是结构体分配在
栈上,而结构体中的引用地址分配在
栈内容还是在堆上。
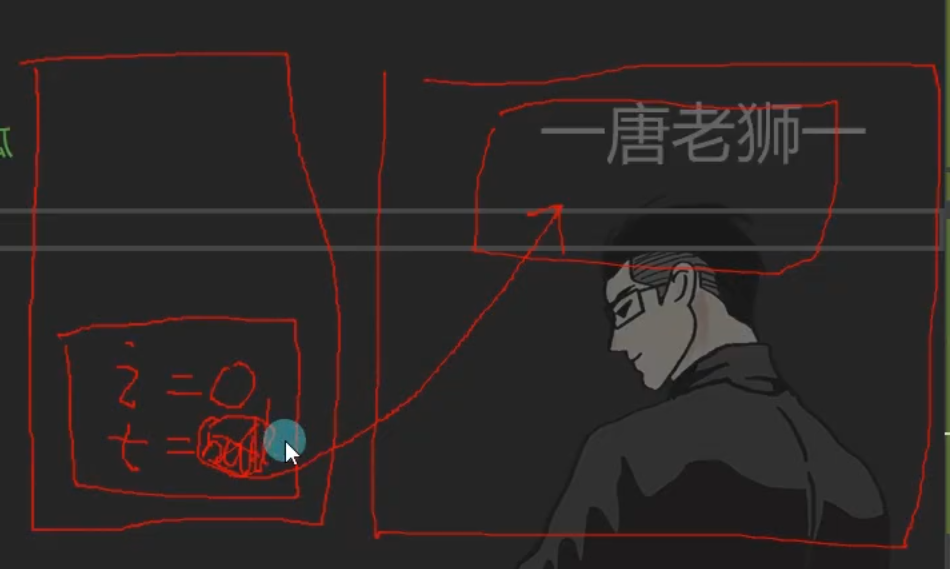
5.问题五 类中的值和引用
类本身是
引用类型在类中的值,
堆中存储具体的值在类中的引用,
堆中存储具体的值总结:
值类型跟着大哥走(引用类型),引用类型一根筋,引用类型都是自己是地址指向分配空间。
2
3
4
5
6
{
int b=0;
string str ="123";
}
Test2 t1=new Test2();
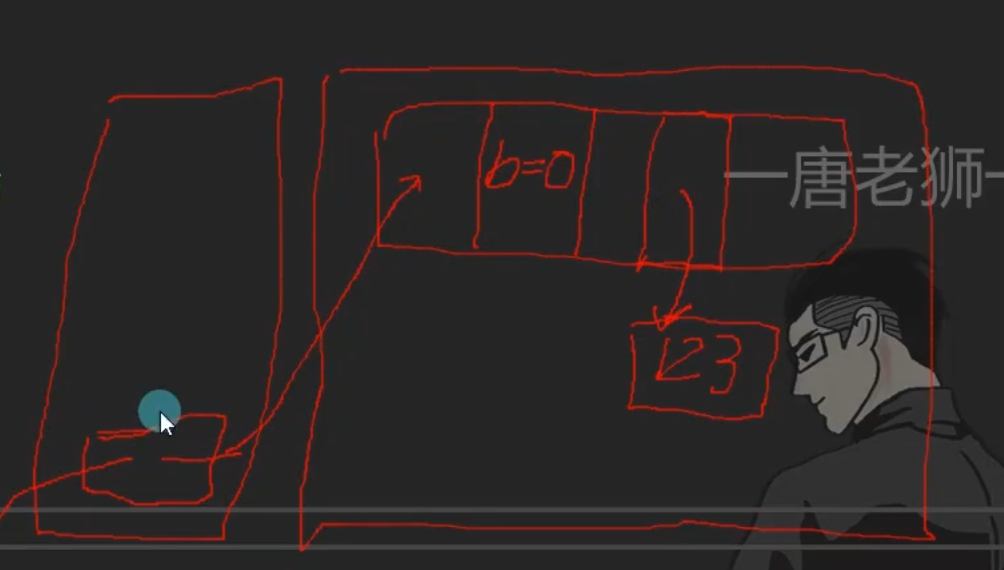
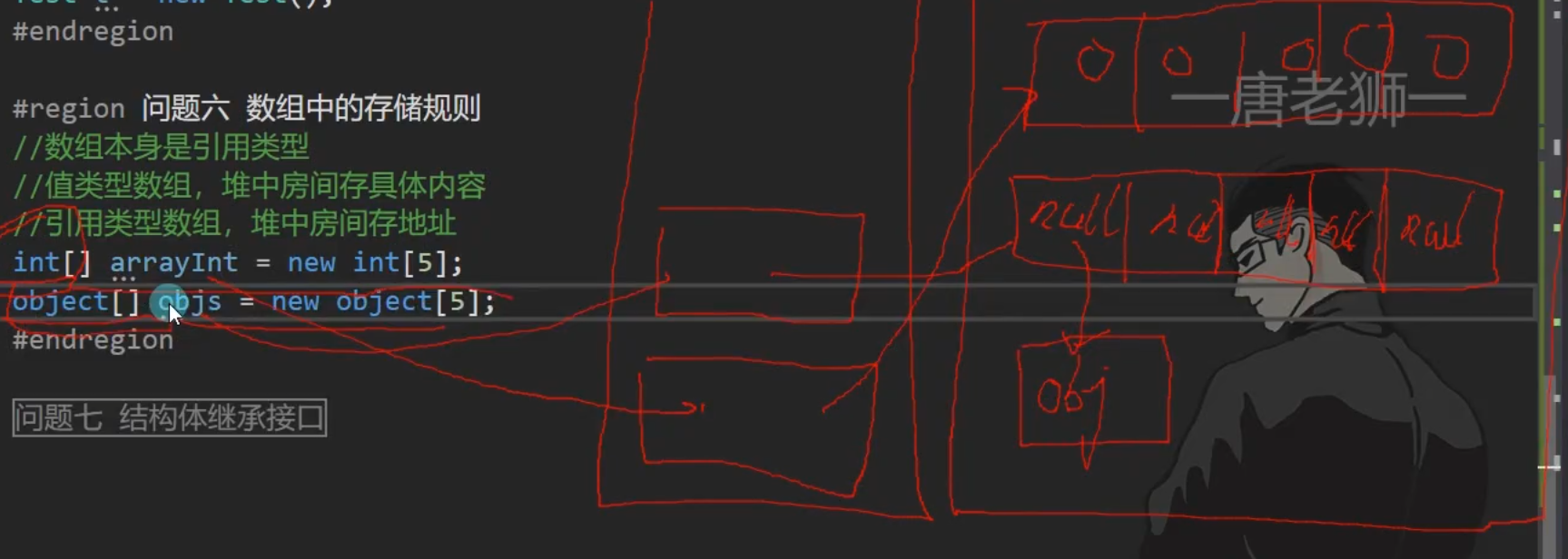
6.问题六 数字中的存储规则
数组本身是引用类型
值类型数组:堆中房间存具体内容
引用类型数组:堆中房间存地址
7.问题七 结构体继承接口
- 注意:利用里氏替换原则,用接口容器装在结构体存在
装箱拆箱
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
int Value
{
get;
set;
}
}
struct TestStruct:ITest
{
int value;
public int Value
{
get{return value}
set{this.value=value}
}
}测试代码
2
3
4
5
obj1.Value=1;
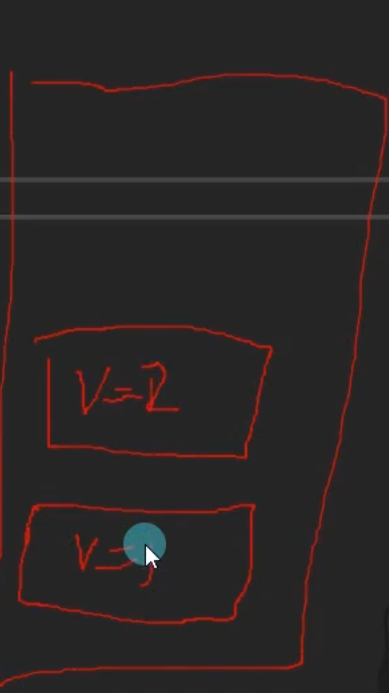
TestStruct obj2=obj1;
obj2.Value=2;
打印obj1.Value和obj2原理:因为分配了两个房间,修改两个互不影响,他是直接复制的obj1的内容
测试代码:
2
TestStruct obj3=(TestStruct)iObj1;//拆箱
四、this关键字的使用
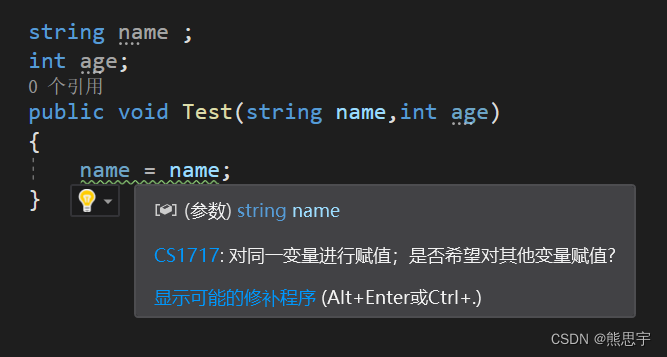
1.区分当前类的对象
如图情况
当出现同名时只要前面加一个 this,系统就知道左边的 name 是当前类的成员,而右边的 name 则是方法的参数。
this代表:当前实例化的具体类
this.name代表:当前实例化的具体类的name成员变量换句话说
this等同于new 类名();
this.name等同于new 类名().name
2.作为参数传递
如果其他类的参数类型和当前类一致,直接写 this 即可
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
public void MyTest(Test2 test2)
{
Console.WriteLine(test2.Name);
}
}
public class Test2
{
public string Name = "厚礼蟹";
public void MyTest()
{
new Test1().MyTest(this);
}
}
3.作为索引器
- 详见
C#索引器==跳转==代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
string[] NameList = new string[3] { "张三", "李四", "王五" };
public string this[int index]
{
get
{
if(index < 0 || index >= NameList.Length)
{
Console.WriteLine("index 的值超过了数组的范围");
return null;
}
return NameList[index];
}
}
}
4.调用其他的构造函数
- 在实例化当前的类的时候,不仅仅是调用一个构造函数,用 this 就可以调用其他的构造函数,甚至在调用的时候,还可以执行其他的属性,字段,调用其他的方法,这些都是没问题的。
代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
{
public class Program
{
static void Main(string[] args)
{
Test1 test1 = new Test1("王五");
Console.ReadKey();
}
}
public class Test1
{
public static int GetAge
{
get => 4;
}
public Test1()
{
}
public Test1(string name, int age)
{
Console.WriteLine("姓名:" + name);
Console.WriteLine("年龄:" + age);
}
public Test1(string name) : this(name, GetAge)
{
}
}
}输出结果为:姓名:王五,年龄:4
五、关于ArrayList,Stack(栈),Queue(队列),Hashtable(哈希表),Dictionary(字典)的总结
1.本质
ArrayList,Stack,Queue,这三个的本质都是C#为我们封装好的类
- 他们三个的本质都是:
object类型的数组
- ArrayList就是个数组
- Stack,先进后出的数组
- Queue,先进先出的数组
Hashtable和Dictionary也是c#为我们封装好的类
- 他们俩的本质:一堆键值对
- Dictionary就是拥有泛型的哈希表
Key Value
2.增删查改(详细官网查文档)
(1).ArrayList
(1).增
- Add();
- Add Range(array);//批量
(2).删
- Remove();//从头删,找到删
- RemoveAt(0);//移除指定位置的元素
- Clear();清空
(3).查看元素是否存在
- array.Contains(“123”);
- int index=array.Indexof(true);//正向查找元素位置,找到的
返回位置,没找到返回-1- index=array.LastIndex();//反向查找元素,返回
从头开始的索引数(4).改
- array[0]=“9888”;
(2).Stack
(1).增(压栈)
- Push(1);
(2).取(弹栈)
注意:栈中不存在删除的概念- 只有取的概念
- Pop();
(3).查
- 只能查看栈顶的内容
- Peek();//并没有弹出
- Contains(1.2f);//查看元素是否存在栈中
(4).改
- 注意:
栈无法改变其中的元素,只能压(存)和弹(取)- 实在要更改,只能清空再压栈
- Stack.Clear();
- Stack.Push();
遍历
- 没有索引器,没法用for循环遍历
- 如何遍历?
- 转为object数组
- object[] array=stack.ToArray();
- 也是从顶到栈底
循环弹栈
2
3
4
{
object o=stack.Pop();
}
(3).Queue
(1).增
- Enqueue(1);
(2).取
注意:
队列中不存在删除的概念,只有取的概念,取出先加入的对象Dequeue();
(3).查
- 查看队列头部元素,但不会移除
Peek();- 查看元素是否在队列中
- queue.Contains(1.4f);
(4).改
- 注意:
队列无法改变其中的元素,只能进出队列,实在要改只有清
- queue.Clear();
- queue.Enqueue(1);
遍历
(1) foreach 遍历
(2) 队列转object数组
- queue.ToArray();
(3) 循环出队
2
3
4
{
queue.Dequeue();
}
(4).Hashtable
(1) 增
- hashtable.Add(1,”123”);
注意:不能出现相同的键(2) 删
- 注意:
只能通过键去删除- hashtable.Remove(1);//传键
删除不存在的键没反应或者直接清空
- hashtable.Clear();
(3) 查
通过键查看值,找不到会返回空
- hashtable[1]
查看是否存在
根据键检测
2
3
4
5
{
}//或者
hashtable.ContainSkey(2);根据值检测
(4) 改
- 注:
只能改键对应的值,无法修改键- hashtable[1]=100.5f;
遍历
hashtable.Count//键值对的对数
遍历所有键
foreach(object item in hashtable.keys) { }
2
3
4
5
* 遍历所有值
* ```C#
foreach(object item in hashtable.values){}键值对一起遍历
foreach(DictionaryEntry item in hashtable){}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
* Hashtable与Dictionary内容差不多具体详细可以查`微软文档`
---
### 3.装箱拆箱
* ArrayList,Stack,Queue本质上都是一个可扩容的object数组,由于用万物之父来存储数据,自然存在拆箱装箱。当往其中进行值类型储存时,就是在装箱。当将值类型对象取出来转换使用时,就是在拆箱。
* `所以这些尽量都少用`,之后我们会学习更好的数据容器《`泛型队列,泛型栈等`》[跳转鼠标左键+ctrl](##八、泛型队列,泛型栈)
---
---
---
## 六、顺序存储和链式存储
### 1. 数据结构
* 简单来说就是`储存数据`和`表示数据之间关系`的规则。
* 常用的数据结构有
* 数组
* 栈
* 队列
* 链表
* 树
* 图
* 堆
* 散列表(类似哈希表)
---
### 2. 线性表
* 线性表是一种数据结构,是由n个具有相同特性的数据元素的有限序列。
* 比如:数组、ArrayList、Stack、Queue、链表。
---
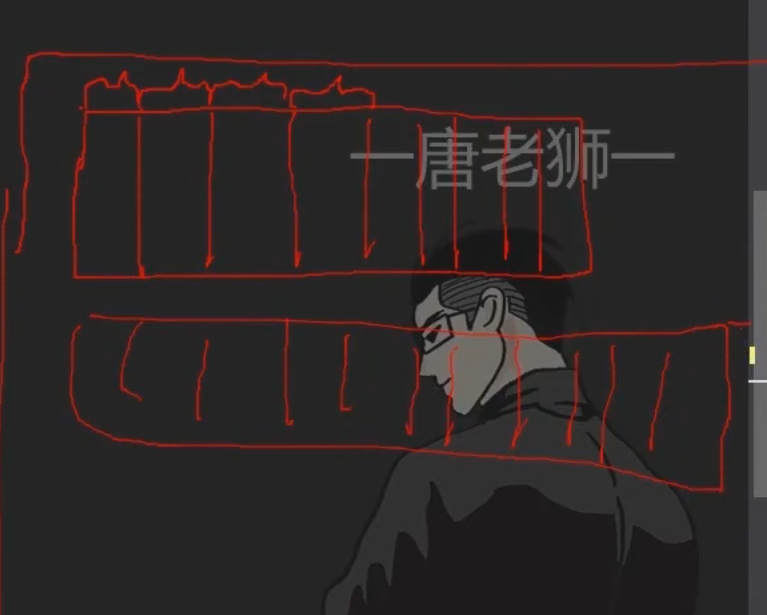
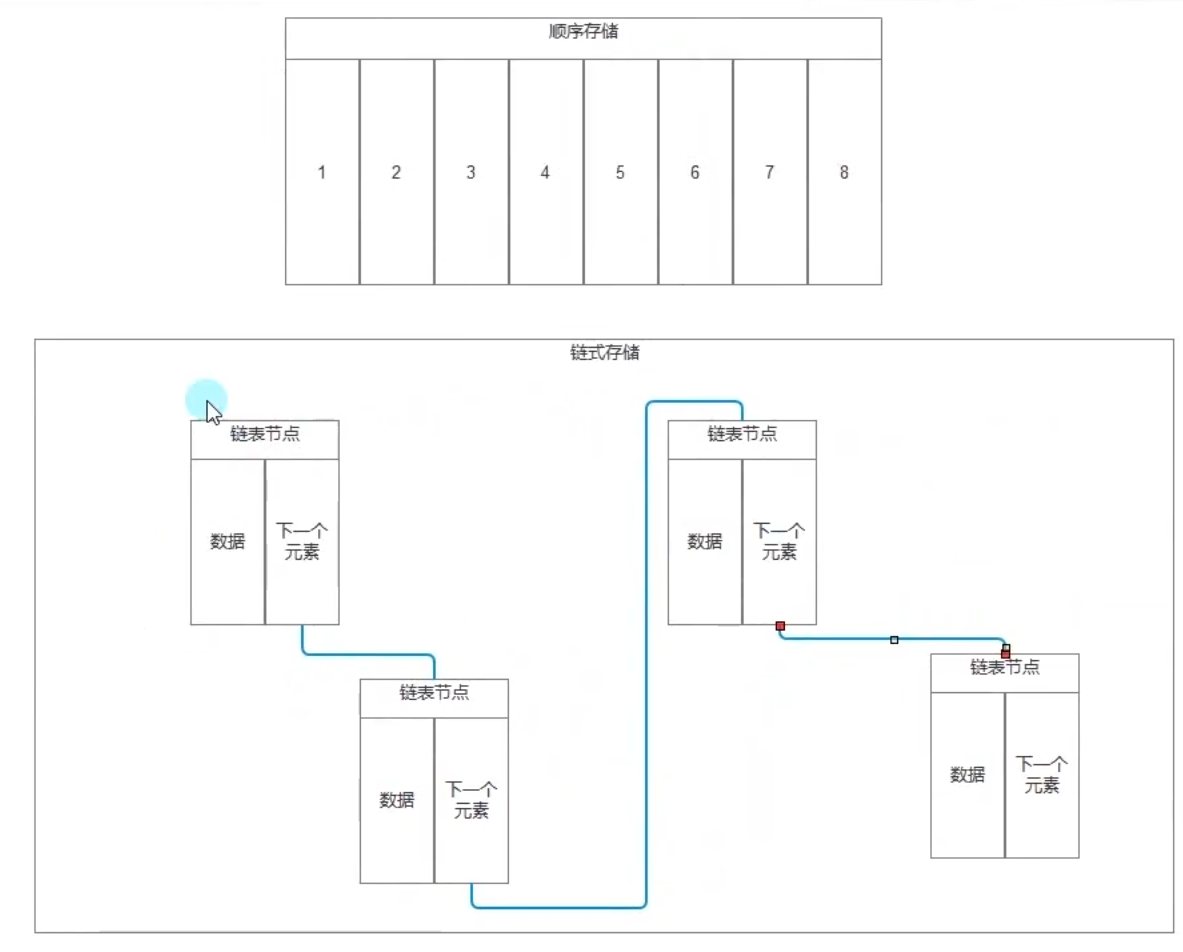
### 3.顺序存储
* (1). 什么叫顺序存储
* 用一组地址连续的存储单元依次存储线性表的各个数据元素。
* 比如:数组、Stack、Queue、List、ArrayList——顺序存储。
* 只是 数组、Stack、Queue的 组织规则不同而已。
---
### 4.链式存储
* (1). 用一组任意的存储单元存储线性表中的各个数据元素。
* 单向链表、双向链表、循环链表——链式存储。
---
### 5. 自己实现一个最简单的单向链表
* 例:
```C#
class LinkedNode<T>
{//单向链表节点
public T value;
//这个存储下一个元素是谁 相当于钩子
public LinkedNode<T> nextNode;
public LinkedNode(T value)
{
this.value=value;
}
}使用:
2
3
LinkedNode<int> node2=new LinkedNode<int>(2);
node.nextNode=node2;
再封装,更好用
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class LindedList<T>
{
public LinkedNode<T> head;
public LinkedNode<T> last;
public void Add(T value)
{
//添加节点 必然是new一个新节点
LinkNode<T> node=new LinkedNode<T>(value);
if(head==null)
{
head=node;
last=node;
}
else
{
last.nextNode=node;
last=node;
}
}
}
七、LinkedList
八、泛型队列,泛型栈
1.普通数据集合
- ArrayList object数据类别
- Stack 栈 先进后出
- Queue 队列 先进先出
- Hashtable 哈希表 键值对
2.泛型数据集合 (常用)
- using System.Collections.Generic;
- List 列表 泛型列表
- Dictionary 字典 泛型哈希表
- LinkedList 双向链表
- Statck 泛型栈
- Queue 泛型队列
3.泛型栈和队列
使用上 和之前的Stack和Queue一模一样。
2
Queue<object> queue=new Queue<object>();
九、类与结构体的区别
1.区别概述
结构体和类最大的区别是在
储存空间上的。因为结构体是
值,类是引用。因此他们的存储位置一个在栈上,一个在堆上。
结构体和类在使用上很类似,结构体甚至可以用面向对象的思想来形容一类对象。
结构体具备着面向对象中
封装的特性,但是它不具备继承和多态的特性,因此大大减少了它的使用频率。由于结构体不具备继承的特性,所以
它不能够使用protected保护访问修饰符。
2.细节区别
- 结构体是值类型,类是引用类型。
- 结构体存在在栈中,类存在堆中。
- 结构体成员不能使用protected访问修饰符,而类可以。
- 结构体成员变量申明不能指定初始值,而类可以。
- 结构体不能申明无参的构造函数,而类可以。
- 结构体申明有参构造函数后,无参构造不会被顶掉。
- 结构体不能申明析构函数,而类可以。
- 结构体不能被继承,而类可以。
- 结构体需要在构造函数中初始化所有的变量,而类随意。
- 结构体不能被静态static修饰(不存在静态结构体),而类可以。
- 结构体不能在自己内部申明和自己一样的结构体变量,而类可以
3. 结构体的特别之处
- 结构体可以继承接口,因为接口是行为的抽象,继承的是一个行为规范。
4.如何选择结构体和类
- 想要用继承和多态时,之间淘汰结构体,比如玩家、怪物等等。
- 对象是数据集合时,优先考虑结构体,比如:位置、坐标等等。
- 从
值类型和引用类型赋值时的区别上去考虑。比如:经常被赋值传递的对象,并且改变赋值对象,原对象不想跟着变化时,就用结构体。比如坐标、向量、旋转等等。
十、C#索引器
1.索引器的基本概念
- 让对象可以像数组一样通过索引房屋内其中元素,使程序看起来更直观,更容易编写
2.索引器语法
1 | 访问修饰符 返回值 this[参数类型 参数名,参数类型 参数名.....] |
3. 索引器内部是可以写逻辑的
例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
{
private string name;
private int age;
private Person[] friends;
public Person this[int index]
{
get
{
//可以写逻辑的,根据需求来处理这里面内容
if (friends == null || friends.Length - 1 < index)
{
return null;
}
return friends[index];
}
set
{
//可以写逻辑的,根据需求来处理这里面内容
//value代表传入的值
if(friends == null)
{
friends = new Person[] { value };
}
else if (index>friends.Length-1)
{
//越界最后一个被顶掉
friends[friends.Length - 1] = value;
}
friends[index] = value;
}
}
}
4.索引器的使用
例:
2
p[0] = new Person();
5.索引器可以重载
例:
public int[,] array; public int this[int i,int j]{ //相当于重载了一个二维int数组 get { return array[i,j] } set { array[i,j]=value; } }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
---
---
---
## 十一、C#迭代器 (Unity异步原理基础)
### 1.迭代器是什么
* 迭代器`(iterator)`有时又称光标`(cursor)`
* 是程序设计的软件设计模式
* 迭代器模式提供一个方法,顺序访问一个聚合对象中的所有元素,又不暴露其内部的标识。
* 在表现效果上看
* 是可以在容器对象(例如:链表或者数组)上遍历访问的`接口`。
* 设计人员无需关心容器对象的内存分配的实现细节
* 注意:
* `可以用foreach遍历的类,都是实现了迭代器的。`
---
### 2. 标准迭代器的实现方法
* 关键接口:IEnumerator,IEnumerable;
* 命名空间:using System.Collections;
* 可以通过同时继承IEnumerator和IEnumerable,实现其中的方法。
例:
```C#
class CustomList:IEnumerable,IEnumerator
{
private int[] list;
//从-1开始的光标,用于表示数据,得到了哪些位置
private int position=-1;
public CustomList()
{
list=new int[]{1,2,3,4,5,6,7,8};
}
//IEnumerable接口实现
public IEnumerator GetEnumerator()
{
//这个只会获取一次
Reset();
return this;
}
//IE numerator接口实现
public bool MoveNext()
{
++position;//移动光标
return position<list.Length;
}
public void Reset()
{
position=-1;//光标复原,用于第一次重置光标位置
//一般写在获取IEnumerator对象这个函数中;
}
public object Current
{
get{return List[position]};
}
}实现:
2
3
4
5
6
7
8
{
CustomList list=new CustomList();
foreach(int item in list)
{
Console.WriteLine(item);
}
}
foreach本质
- 1.先获取in后面这个对象的 IEnumerator,会调用对象其中的GetEnumerator方法 来获取。
- 2.执行得到这个IE numerator对象中的 MoveNext方法
- 只要MoveNext方法的返回值是true,就会去得到Current;
- 4.然后把Current赋值给item
3. 用yield return 语法糖实现迭代器
yieldreturn
- 是C#提供给我们的语法糖,所谓语法糖,也称糖衣语法。
主要作用:
- 将复杂逻辑简单化,可以增加程序的可读性。从而减少程序代码出错的机会
关键接口:
IEnumerable让想要通过foreach遍历的自定义类实现接口中的方法GetEnumertor即可,不需要去实现另外的方法。
- 比如:Current,MoveNext()
例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
private int[] list;
public CustomList2()
{
List=new int[]{1,2,3,4};
}
public IEnumerator GetEnumerator()
{
for(int i=0;i<list.length;i++)
{
yield return list[i];
//yield 关键字 配合迭代器使用
//可以理解为暂时返回,保留当前状态,符合走走停停的特性
}
}
}==本质==
- yield return 会自动生成我们需要的代码
4.用泛型类实现迭代器 (同样的)
例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
private T[] array;
public CustomList(params T[] array)
{
this.array=array;
}
public IEnumerator GetEnumerator()
{
for(int i=0;i<array.length;i++)
{
yield return array[i];
}
}
}
十二、C#接口 (框架必备)
1.接口的概念
- 关键字:
interface- 接口是
行为的抽象规范- 它也是一种自定义类型
- (1) . 接口申明规范
- ①不包含成员变量。
- ②只包含方法、属性、索引器、事件。
- ③成员不能被实现。
- ④成员可以不用写访问修饰符,不能是私有的。
- ⑤接口不能继承类,但可以继承另一个接口。
(2) . 接口的使用规范
- ①类可以继承
多个接口- ②类继承接口后,
必须实现接口中的所有成员- ③接口继承接口时,不需要实现。待类继承接口后,类自己去实现
(3) . 特点
- ①
和类的申明类似- ②
接口是用来继承的- ③
接口不能被实例化,但可以作为容器存储对象
2.接口的申明
接口关键字:interface
语法:
一句话记忆:
接口是抽象行为的“基类”接口命名规范:帕斯卡命名法:
前面加个I例1:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
void Fly();//不写访问修饰符,默认public,并且不能私有,因为要实现
//属性
string Name
{
get;
set;
}
//索引器
int this[int index]
{
get;
set;
}
}
3.接口的使用
- (1). 类可以继承1个类,n个接口
- (2) . 继承了接口后必须实现其中的内容并且必须是
public- (3) . 接口的实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Person:Animal,IFly
{
void Fly(){}
string Name
{
get;
set;
}
int this [int index]
{
get
{
return 0;
}
set;
}
}注意:如果加protected必须显式实现接口
- (4) .实现的接口函数可以再加V,再在子类重写
- (5). 可以通过接口存取不同类型的对象,因为接口
遵循里氏替换原则
- IFly f=new Person();
4.显示实现接口
当一个类继承两个接口,但是接口中存在着同名方法时
接口内方法访问修饰符为protect
显示实现接口 就是用 接口名.行为名 去实现
注意
显式实现接口时,不能写访问修饰符
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
void Atk();
}
interface ISuperAtk
{
void Atk;
}
class Player:IAtk,ISuperAtk
{
void IAtk.Atk()
{
}
void ISuperAtk.Atk() {
}
}注意:
我们直接用Player类是调用不出来Atk()这个方法的,必须要as 成父类
2
(p as IAtk).Atk();
5.总结
- 继承类:是对象间的继承,包括行为特征等等
- 继承接口:是
行为间的继承,继承接口的行为规范,按照规范去实现内容- 由于
接口也是遵循里氏替换原则,所以可以用接口容器装对象- 那么就可以实现,装载
各种毫无关系但是却有相同行为的对象- 注意:
- 接口只包含成员方法、索引器、事件,并且都不实现,都没有访问修饰符。
- 可以继承多个接口,只能继承一个类
- 接口可以继承接口,相当于进行
行为合并,待子类继承时再去实现具体的行为- 接口可以被显示实现,主要用于实现不同接口中同名函数的不同表现。
- 实现的接口方法 可以加 virtual关键字 之后子类再重写。
十三、c#委托 (框架必备)
1.什么是委托
- 委托
是函数(方法)的容器。
- 理解:表示函数(方法)的变量类型,用来储存、传递函数(方法)
- 就像int a,string str一样,一个变量
- 本质:
- 委托的本质就是
一个类- 用来定义
函数(方法)的类型(返回值和参数的类型)- 不同的函数(方法)必须对应和各自“格式”一致的委托;
2.基本语法
- 关键字:
delegate- 语法:(委托函数申请语法)
- 访问修饰符 delegate 返回值 委托名 (参数列表);
写在哪里?
- 可以申明再namespace中和class语句块中
- 更多的写在namespace中
- 简单记忆:
- 委托语法就是
函数声明语法前面加上一个delegate关键字
3.定义自定义委托
注意:
- 访问修饰符
默认不写为public在别的命名空间也能使用- private在其他的命名空间就不能用了,一般使用public
例1.
申明了一个可以用来存储
无参无返回值的函数容器注:这里只是定义了规则并没有使用
delegate void MyFun();
2
3
4
5
6
7
8
9
10
11
12
13
---
* 例2.
* 委托规则的申明`是不能重名的(同一语句块中)`
* 表示用来装载或者传递返回值为int
* 有一个int参数的函数的委托容器规则
* ```C#
public delegate int MyFun2(int a);
4.定义好的委托的使用
例1
MyFun f=new MyFun(Fun); f.Invoke();//调用委托内的函数 static void Fun(){}//格式必须与定义的一致
2
3
4
5
6
7
8
---
* 例2
* ```C#
MyFun f2=Fun;
f2();//直接传入函数(方法),之后直接调用委托函数。MyFun f3=Fun2; f3(2); static int Fun2(int value) { return value; }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
---
### 5.委托常用在哪里?
#### (1). 作为类的成员
* 例:
* ```C#
class Test
{
public MyFun fun;
public MyFun2 fun2;
}
(2). 作为函数的参数
例:
class Test { public MyFun fun; public MyFun2 fun2; public void TestFun(MyFun fun,MyFun fun2) { //可以先处理一些别的逻辑及,当这些逻辑处理完了,再执行传入的函数 int i=1; i*=2; i+=2; //处理完成 fun(); fun2(i); //也可以存起来 this.fun=fun; this.fun2=fun2; } }
2
3
4
5
6
7
8
9
10
11
12
---
### 6.委托变量可以存储多个函数(多播委托)
#### (1). 如何用委托存储多个函数
* 例:
* ```C#
MyFun ff=Fun;
ff+=Fun;//ff中会存两个Fun函数理解:委托就是先处理自己的逻辑,之后再批量处理别人的逻辑
(观察者模式)
例1. 增
public void AddFun(MyFun fun,MyFun2 fun2) { this.fun+=fun; this.fun2+=fun2; }//会按增加的顺序执行
2
3
4
5
6
7
8
9
10
11
---
* 例2. 删
* ```C#
Public void RemoveFun(MyFun fun,MyFun2 fun2)
{
this.fun-=fun;
this.fun2-=fun2;
}
(2). 注意
如果委托是空的会
报错,要执行委托之前最好判空一下
2
if(ff!=null){ff();}注:多减不会报错 无非就是不处理,因为找不到。
7.系统提供的委托
注:
使用系统自带委托需要引用命名空间 using system;
- Action
- 无参无返回值的委托
- Fun<> 泛型委托
- 任意类型返回值,无参
注意:委托是支持泛型的,可以让返回值和参数可变
举例:
delegate T MyFun3<T,K>(T v,K k);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
----
* 3. 可以传n个参数的 (1-16个参数的委托)
* Action<int>
* Action<…, …, ..,>
* Action<int,string,bool>
* 4. 可以传n个参数的 并且 有返回值的 系统也提供了16个委托
* Fun<int,string> 前面是参数,最后是返回值
* `这里的第一个都是逆变in传入参数,第二个是协变out返回值`
---
### 8.总结
* 简单理解
* `委托就是装载,传递函数的容器而已。`可以用委托变量来存储函数或者传递函数,系统已经提供了很多委托给我们用
---
---
---
## 十四、C#事件 (框架必备)
### 1.事件是什么
* 事件是`基于委托的存在`
* 事件是`委托的安全包裹`
* 让委托的使用更具有`安全性`
* 事件是一种`特殊的变量类型`,他也是存储函数的变量
---
### 2.事件的使用
* 申明语法:
* ```C#
访问修饰符 event 委托类型 事件名
事件的使用
- 事件是作为
成员变量存在于类中- 委托怎么用 事件就怎么用
事件相对于委托的区别
不能再类外部赋值
不能在类外部调用
- ==注==:它只能
作为成员存在于类和接口以及结构体中。- ==注==:事件是
不能作为临时变量在函数中使用的。例:
class Test { //委托成员变量 用于存储函数的 public Action myFun; public event Action myEvent;//事件成员变量用于存储函数的 public void TestFun() { } public Test() { //事件的使用和委托一模一样,只是有些细微的区别 myFun=TestFun; myFUn+=TestFun; myFun-=TestFun; myFun(); myFun.Invoke(); myFun=null; myEvent=TestFun; myEvent+=TestFun; myEvent-=TestFun; myEvent(); myEvent.Invoke(); myEvent=null; } }---
2
3
4
5
6
7
8
9
10
11
12
* 虽然事件不能在外面直接赋值,但是可以`加减去添加移除记录的函数`
* ```C#
class Progame
{
//委托可以在外面调用,事件不能再外部调用
Test t=new Test();
t.myEvent+=TestFun
static void TestFun(){}
}
如果想在类外面调用事件,可以先在类中封装一个方法
public void DoEvent() { if(myEvent!=null) myEvent(); }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
---
### 3.为什么要有事件
* `防止外部随意滞空委托`
* `防止外部随意调用委托`
* `事件相当于对委托进行了一次封装,让其更安全`
---
### 总结
* 事件和委托的使用基本上一模一样
* 事件就是特殊的委托
* 主要区别:
* 事件不能在外部赋值,不能使用=符号。只能使用+=,-=。而委托哪里都能用
* 事件不能在外部执行,委托哪里都能执行
* 事件不能作为函数的临时变量,委托可以
---
---
---
## 十五、协变 逆变
### 1. 什么是协变逆变
* (1). 协变
* 和谐的变化,自然的变化
* 因为里氏替换原则 父类可以装子类
* 所以 子类变父类
* 比如:string 变成 object,感觉是和谐的
----
* (2). 逆变
* 逆常规的变化,不正常的变化
* 因为 在里氏替换原则中 父类可以装子类,但是子类不能装父类
* 所以 父类变子类
* 比如:object 变成 string
* 感觉是不和谐的
---
* (3). 协变和逆变是用来修饰泛型的
* 协变:out
* 逆变:in
* 用于在泛型中 修饰 泛型字母的
* 只有泛型接口和泛型委托能用
---
---
### 2.返回值和参数
* (1). 用out修饰的泛型 `只能作为返回值`
* 例:
* ```C#
delegate T TestOut<out T>();
(2). 用in修饰的泛型
只能作为参数
例:
delegate void TestIn<in T>(T t);---
2
3
4
5
6
7
8
9
10
11
12
---
* (3). 接口中的协变
* 例:
* ```C#
interface Test<T>
{
T TestFun();
}
3.结合里氏替换原则理解
(1). 协变 父类总是能被子类替换
例:
class Father{} class Son:Father{}
2
3
4
5
6
7
8
9
10
11
* ```C#
TestOut<Son> os=()=>
{
return new Son();
};
TestOut<Father> of=os;
Father f=of();这个out会帮助我们判断这个返回值有没有父子关系。
看起来就是返回值 就是son=》father
实际上返回的是os里面的son,但是用父类装了子类
逆变 父类总是能被子类替换
例:
TestIn<Father> iF=(value)=> { //参数类型为father }; TestIn<Son> iS=iF; iS(new Son());//实际上调用的是iF,但是传入的是子类Son //像是子类泛型委托装载父类泛型委托
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
* 看起来好像是father =》son 明明是传父类但是你传入子类就是不和谐的
---
---
### 4.总结
* 作用两点:
* (1). out 修饰的泛型的泛型类型只能作为返回值类型,in只能作为参数类型
* (2). 遵循里氏替换原则的,用out和in修饰的泛型委托可以相互装载(有父子关系的泛型)
* 协变:out 父类装子类
* 逆变:in 子类装父类
* 用来修饰泛型替代符的只能修饰接口和委托中的泛型。
---
---
---
## 十六、多线程
### 1. 什么是进程呢
* 进程
* 是计算机中程序关于`某数据集合上的一次运行活动`。
* 是系统进行`资源分配和调度的基本单位`
* 是`操作系统结构的基础。`
* 说人话:
* 打开一个应用程序就是在操作系统上开启了一个进程。
* 进程之间可`以相互独立运行`,`互不干扰`
* 进程之间也`可以相互访问、操作`
* 
---
---
### 2. 什么是线程
* 线程
* 操作系统能够进行运算调度的`最小单位`
* 它被包含在进程中 是进程中的`实际运作单位`
* 一条线程:
* `进程中一个单一顺序的控制流,一个进程中可以并发多个线程`
* 我们目前所写的程序 `都在主线程中`
* 简单理解线程:
* 就是代码从上到下运行的一条“管道”

---
---
### 3. 什么是多线程
* 我们可以通过代码开启新的线程
* 可以同时运行代码的多条“管道” 就叫多线程
---
### 4. 语法相关
* 线程类:`Thread`
* 需要引用命名空间 using System.Threading
#### (1). 申明一个新的线程
* 注:`线程执行的代码需要封装到一个函数中`。`新线程将要执行的代码逻辑,被封装到了一个语句块`
* ① 申请一个线程
```C#
Thread t=new Thread(NewThreadLogic);
static void NewThreadLogic()
{
//新开的线程执行的代码逻辑在该语句块中
}
(2). 启动线程
1 | t.Start(); |
(3). 设置为后台线程
当前台线程都结束了的时候,整个程序也就结束了,即使还有后台线程正在运行。
后台线程不会防止应用进程被中止掉
如果不设置为后台线程,可能导致进程无法正常关闭
t.IsBackground=true;--- * 第二种:通过线程提供的方法 (注:`在.Net Core版本中无法中止会报错`)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
注:当主线程跑完,如果你开启的线程是死循环并且没有设置为后台线程。那么该`线程会因为无法跳出线程函数`而导致`进程无法关闭!!!`
`设置完后台之后,前台线程跑完将自动结束后台线程`(自动跳出后台线程)
---
#### (4). 关闭释放一个线程
* ① 如果开启的线程中不是死循环,是能够结束的逻辑。那么,不用刻意的去关闭它。
---
* ② 如果`是死循环想要中止这个线程`,有两种方式
* 第一种:死循环中bool标识
```C#
static bool isRunning=false;
static void NewThreadLogic()
{
while(isRunning)
{
//逻辑
}
}
2
t=null;
(5). 线程休眠
在哪个线程中执行,就休眠哪个线程
5. 线程之间共享数据 加锁(很重要)
多个线程使用的内存
是共享,都属于该应用程序(进程)。所以要注意,当多线程同时操作一片内存区域时,可能会出问题。
可以通过
加锁的形式避免问题
当我们在多个线程中想要访问同一个东西进行逻辑处理时,为了避免不必要的逻辑顺序执行的差错
2
3
4
5
6
7
8
9
10
11
12
static void NewThreadLogic()
{
while(true)
{
lock(obj)
{
//要先检测有没有锁住的obj,如果没有,将执行lock语句块
//通过锁住同一个引用对象的方式,强制让多线程按顺序执行;
}
}
}
6. 多线程对于我们的意义
可以用多线程专门处理一些复杂耗时的逻辑。比如:寻路、网络通信
十七、反射 (Unity编译器运行原理基础)
1. 必备概念知识回顾
- 编译器是一种
翻译程序- 它用于
将源语言程序翻译为目标语言程序源语言程序:
- 某种程序设计语言写成的。比如:C#,C,C++
目标语言程序:
- 二进制数表示的伪机器 代码写的程序。
2.什么是程序集
- 程序集是经由编译器编译得到的,供进一步编译执行的那个中间产物。
- 在windows系统中,它一般表现为后缀为.dll(库文件)或者是.exe(可执行文件)的格式。
说人话:
- 程序集就是我们写的一个代码集合,我们现在写的所有代码最终都会被编译器翻译成一个程序集供别人使用。
- 比如:一个代码库文件(dll)或者一个可执行文件(exe)
3.元数据
- 元数据就是用来描述数据的数据
- 这个概念不仅仅用于程序上,在别的领域上也有元数据
- 说人话:
- 程序中的类、类中的函数、变量等等信息就是 程序的元数据。
- 有关程序以及类型的数据被称为元数据,它们保存在程序集中。
4.反射的概念
- 程序正在运行时,可以查看其它程序集或者自身的元数据。
- 什么叫做反射???
- 一个
运行的程序查看本身或者其它程序的元数据的行为叫做反射。- 说人话:
- 在程序运行时,通过反射可以得到其它程序集或者自己程序集代码的各种信息。
- 比如:类、函数、变量、对象等等。实例化他们,执行他们,操作他们。
- 自己运行时,可以得到自己代码和别人代码
5.反射的作用
因为反射可以在程序编译后获得信息,所以
它提高了程序的拓展性和灵活性。
(1). 程序运行时得到所有元数据,包括元数据的特性。
(2). 程序运行时,实例化对象,操作对象。
(3). 程序运行时创建新对象,用这些对象执行任务。
6.语法相关
准备代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
private int i=1;
public int j=0;
public string str="123";
public Test()
{
}
pulic Test(int i)
{
this.i=i;
}
public Test(int i,string str):this(i)
{
this.str=str;
}
public void Speak()
{
Console.WriteLine(i);
}
}
(1). Type类
1.Type(类的信息类)
它是反射功能的基础。
他是访问元数据的主要方式。
使用Type的成员获取有关类型声明的信息、有关类型的成员(如:构造函数、方法、字段、属性和类的事件)
- 获取Type
(1). 万物之父object中的GetType() 可以获取对象的Type
例:
2
3
Type type1=a.GetType();
Console.WriteLine(type);//System.Int32(2). 通过type of关键字 传入类名 也可以得到对象的Type
例:
2
Console.WriteLine(type2);(3). 通过类的名字 也可以获取类型
注意:类名必须包含命名空间 不然找不到
例:
2
Console.WriteLine(type3);
疑问:type1、type2、type3相等不?答:
相等,它们指向的为同一地址,因为Type的引用类型。
- 得到类的程序集信息
可以通过Type得到类型所在程序集的信息例:
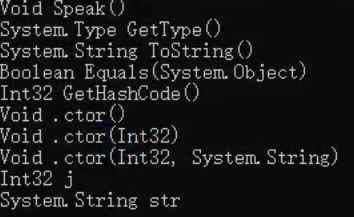
- 获取类中的所有公共成员
(1) 首先得到Type
(2) 然后得到所有公共成员
- 注:
需要引入命名空间,using System.Reflection
2
3
4
5
for(int i=0;i<infos.Length;i++)
{
Console.WriteLine(infos[i]);
}
注:
ctor是构造函数
- 获取类的公共构造函数并调用
(1). 获取所有构造函数
2
3
4
5
for(int i=0;i<ctors.Length;i++)
{
Console.WriteLine(ctors[i]);
}(2). 获取其中一个构造函数并执行
得构造函数传入Type数组,数组中内容按顺序是参数类型。
执行构造函数传入object数组,表示按顺序传入的参数。
① 得到无参构造
② 执行无参构造/无参构造 没有参数 传null;
2
//它得到了是object对象,父类装子类,用里氏替换原则as 成子类Test
③ 得到有参构造函数
④ 执行有参构造函数
例:整体实现
2
obj=info3.Invoke(new obj[]{2,"asd"}) as Test;
(2). 获取类的公共成员变量
① 得到所有成员变量
2
3
4
5
6
7
FieldInfo[] fieldInfos=t.GetFields();
for(int i=0;i<fieldInfos.Length;i++)
{
Console.WriteLine(fieldInfos[i]);
}
② 得到指定名称的公共成员变量
③ 通过反射获取和设置对象的值
2
3
4
5
6
7
test.j=99;
test.str="123";
//通过反射获取对象的某个变量
infoJ.GetValue(test);//直接传入对象,就可以获取j的值。这个主要是获取别的程序集
//通过反射设置指定对象的某个变量的值
infoJ.SetValue(test,100);
(3). 获取类的公共成员方法
通过Type类的
GetMethod方法,得到类中的方法,MethodInfo是方法的反射信息注意:如果存在方法重载,用Type数组表示参数类型
2
MethodInfo[] methods=strType.GetMethods();例:
调用该方法
注意:如果是静态方法
Invoke中第一个参数传null即可;
2
3
//第一个参数相当于是哪个对象要执行这个成员方法
substr.Invoke(str,new object[] {7,5});
面向对象开发思想
一、面向对象(oop)和面向过程(pop)编程的区别
1.抽象级别
- oop:
- 将现实事件的概念
抽象为对象,每个对象都具有自己的属性和方法。- 例如:
- 一个汽车对象可以拥有属性(颜色、品牌、马力)和方法(加速、刹车、转弯)
- pop:
- 侧重于描述问题的
解决步骤和实现细节
二、UML类图
1.什么是UML
- UML(Unified Modeling Language)
- 统一建模语言
- 是一种为面对对象系统的产品进行说明、可视化和编写文档的一种标准语言,是非专利的第三代建模和规约语言。
- UML是面向对象设计的建模工具,独立于任何具体程序设计语言
- 简单理解:
- 使用一些高级的UML可视化软件,不用写代码,通过做一些图表相关内容就可以直接生成代码,并在其基础上进行开发。
- 他的终极目标是直接能通过图像就把业务逻辑
完成
2.UML类图
- UML类图是UML其中很小的一部分
- 我们学习他的目的是:
- 帮助我们进行面向对象程序开发时,理清对象关系,养成面向对象编程习惯
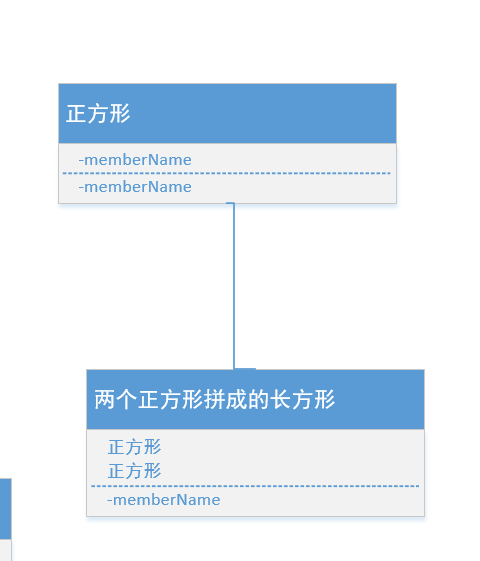
3.关联说明
(1).关联(B使用A,松散关系,B和A没有强联系)
- 比如类A会有一个类b成员作为他的成员变量
- 使用说明
(2).直接关联(A影响B的行为)
- 举例:
- 比如母鸡类中有一个行为是下单,它和气候直接关联
- 图例:
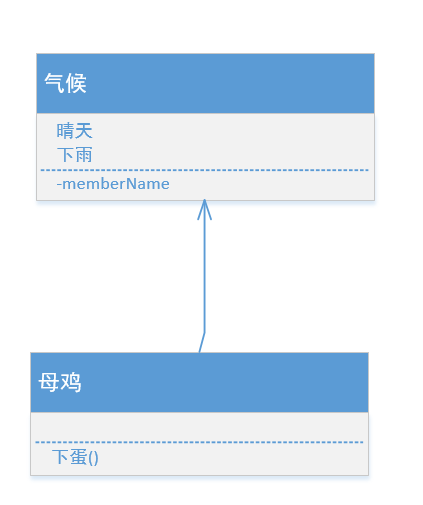
(3).聚合(B包含A)
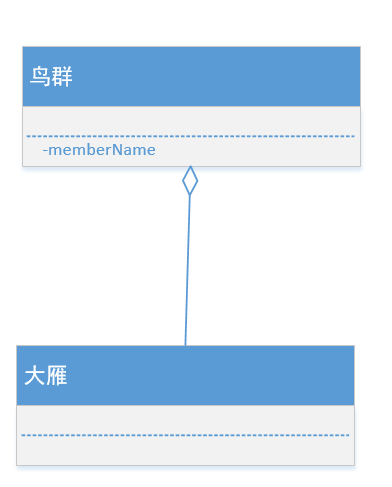
- 举例:比如地图类聚合围墙类,鸟群类聚合大雁类==(有点包含的意思)==
- 图解
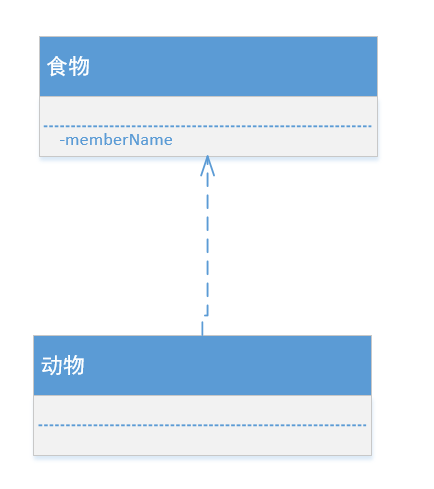
(4).依赖关系 (B依靠A存在)
- 举例:
- 比如动物类依赖于空气类和水类(通俗解释:==没有不行==)
- 图例:
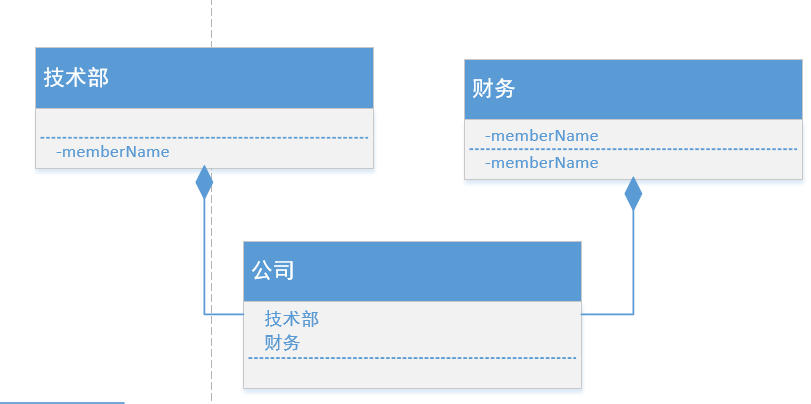
(5).复合 (A+B+C+D+….=N,强关联,N与其他部分不可分割的关系)
- 比如公司类包含各种部门类
- 部门类和公司的关系就是复合关系
- 表示一个类(整体)由另外一个类的对象(部分)组成
- 图例
三、面向对象七大原则
为什么要有七大原则?
- 七大原则总体要实现的目标是:
- ①高内聚
- ②低耦合
- ③使程序模块的可重用性,移植性增强
- 如何理解
高内聚、低耦合?
- ①从类的角度看:
减少类内部,对于其他类的调用- ②从功能块看:
减少模块之间的交互复杂度(相互依赖度低)
1.单一职责原则(SRP)
类被修改的几率很大,因此
应该专注单一的功能。如果把多个功能放在同一个类中,功能之间就形成的关联,改变其中一个功能,有可能中止另一个功能。
举例:
假设程序、策划和美术,三个工种是三个类,他们应该各司其职。在程序世界中只应该做自己应该做的事情。
如果程序和策划写在一起,突然我的策划数值要改,我的程序代码要用到策划数据,可能会造成麻烦
假设你在开发一款角色扮演游戏,游戏中的技能系统由程序和策划模块共同设计和实现。在游戏最初的设计中,角色A的火球术技能是造成100点火焰伤害,消耗50点法力值,并有10秒的冷却时间。这些具体的数据和规则被写死在程序代码中,作为策划内容的一部分。
现在,游戏策划师认为火球术技能的伤害值过低,需要修改为200点火焰伤害。在这种情况下,由于策划内容和程序逻辑耦合在一起,策划师想要修改火球术技能的数据,就需要程序员修改程序代码中对应的实现部分,才能实现新的策划设定。这样的耦合性使得程序的修改与策划内容的修改相互依赖,增加了系统的脆弱性和维护成本。
2.开闭原则(ocp)
对拓展开放,对修改关闭
- (1) 拓展开放
- 模块的行为可以被拓展,从而满足新的需求。(
VOB)- (2) 修改关闭
- 不允许修改模块源代码(或者尽量使修改最小化)
- 举例:
继承(Vob)就是最典型的开闭原则的体现,可以通过添加新的子类和重写父类的方法来实现
3.里氏替换原则(LSP原则)
- 详细请见里氏替换原则思想详解;
(暂未补充)
- 思想:
任何父类出现的地方,子类都能替代- 举例:
- 用父类容器装载子类对象,因为子类对象包含了父类的所有内容。
- 理解:
父类用子类替——行为没有发生变化
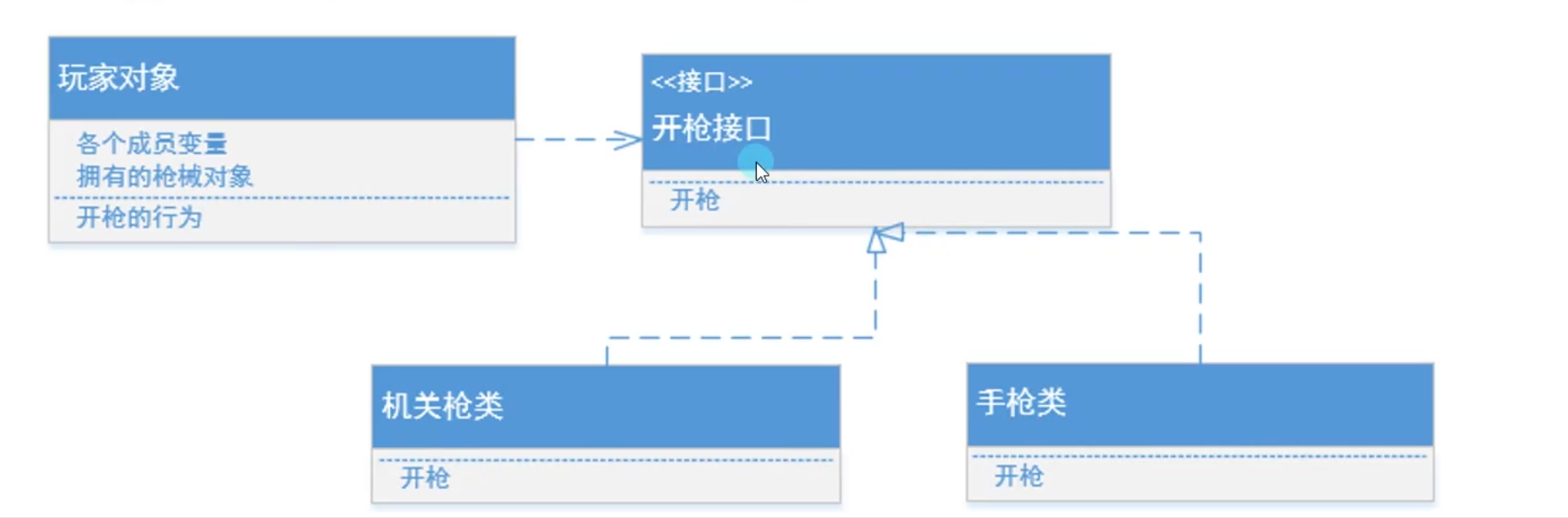
4.依赖倒转原则(DIP)
- 思想:
要依赖于抽象,不要依赖于具体实现- 理解:
- 人要开枪,是依赖于枪械的,倒转之后是去依赖于开枪的行为,而不是具体。
- UML图解
5.迪米特原则(LOP,又称最少知识原则)
- 思想:
一个对象应当对其他对象尽可能少的了解,不要和陌生人说话。- 举例:
- 一个对象的成员,要尽可能少的直接和其他类建立关系,目的是降低耦合度
6.接口分离原则(ISP)
- 思想:
不应该强迫别人依赖他们不需要使用的方法- 理解:
- 一个接口不需要提供太多的行为,
一个接口应该尽量只提供一个对外的功能,让别人去选择需要实现什么样的行为,而不是把所有的行为封装到一个接口当中- 总结:
一个行为一个接口,不要一个接口n个行为- 举例:
- 飞行接口,走路接口,跑步接口等。虽然他们都是移动的行为,但是我们应该把他们分成一个一个单独的接口,让别人去使用。
因为接口继承之后,必须要实现,我们没有必要去继承一个很多行为的接口,去实现很多没有必要的行为。
7.合成复用原则(CRP)
- 思想:
尽量使用对象组合,而不是继承来达到复用- 注意:继承是
强耦合,组合关系是低耦合- 举例:
- 脸是由鼻子,嘴组成的,而不是继承。
- 注意:
不要盲目的使用合成复用原则,要在遵循迪米特原则(最少知识原则)的前提下。除非设计上需要继承,否则尽量用组合复用的形式
8.如何使用这些原则
注意:七大原则不是相互配合,而是根据需求自己进行选择。
- 在开始做项目之前,整理UML类图时,先按自己的想法把需要的类整理出来。
- 再把七大原则截图放在旁边,基于七大原则去优化整理自己的设计
- 整体目标就是:
高内聚,低耦合- 初学阶段:
- 不要过多的纠结于七大原则
- 先用最适合自己的方法把需求实现了
- 再使用七大原则去优化
不要想着一步到位